万字长文!我的校招算法岗面经总结!
用通俗易懂的方式讲解:NLP 这样学习才是正确路线
保姆级教程,用PyTorch和BERT进行文本分类
保姆级教程,用PyTorch和BERT进行命名实体识别
一网打尽:14种预训练语言模型大汇总
盘点一下 Pretrain-Finetune(预训练+精调)四种类型的创新招式!
NLP中的数据增强方法!
总结!语义信息检索中的预训练模型
深度梳理:实体关系抽取任务方法及SOTA模型总结!
【NLP】实体关系抽取综述及相关顶会论文介绍
【深度总结】推荐算法中的这些特征工程技巧必须掌握!
12篇顶会论文,深度学习时间序列预测经典方案汇总
一文梳理推荐系统中的特征交互排序模型
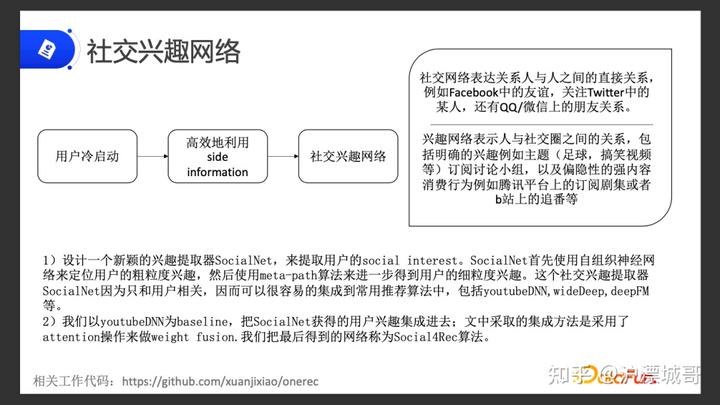
02 社交兴趣网络

图片
针对用户冷启动有两个解决方法:
除了 ID 信息以外,通常把用户属性特征,比如年龄、性别,还有额外的一些东西补充到模型中去训练,这是利用 Side Information 的一个方式。
我们没办法拿到更多的 Side Information,因此要高效地利用现有的 Side Information,来提升效果。
接下来将重点讲解如何高效地利用 Side Information。这就引出了我们今天要讲的社交兴趣网络。
图片
社交兴趣网络主要分为两个部分:
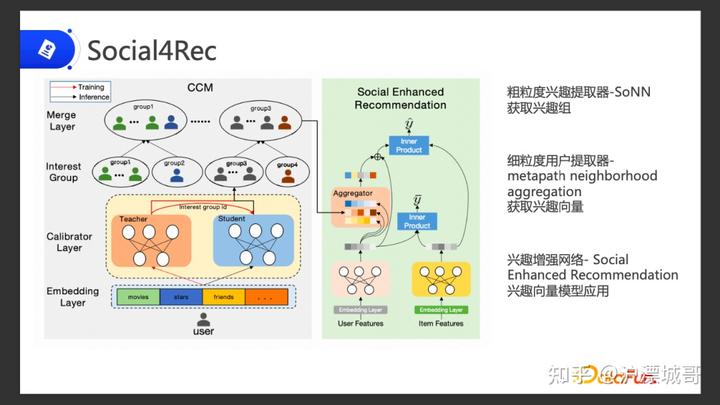
我们提出了兴趣抽取器SocialNet,来抽取用户的社交兴趣。这个抽取器是一个可集成到其他推荐算法中的非常实用的组件。在这基础上,我们选取了YouTube DNN 做 baseline,把 SocialNet 获得的用户兴趣集成进去,通过 attention 的方式来进行权重融合,得到最终的网络,叫做 Socail4Rec。下面来详细介绍这一算法。
03Socail4Rec1.算法模型的概览图
图片
模型的总体概览图如上所示,其中包含三个部分:
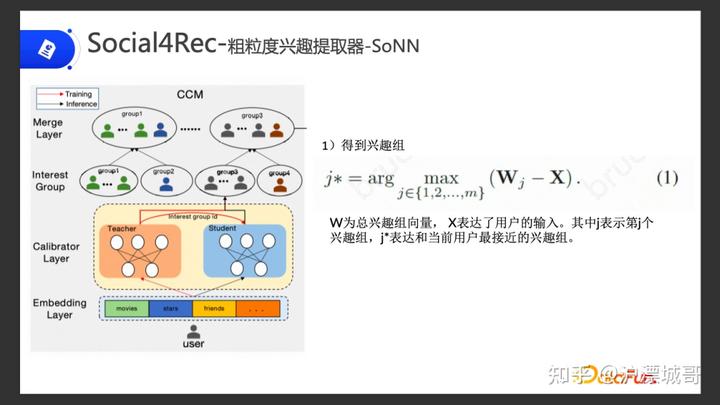
2.Social4Rec-粗粒度兴趣提取器-SoNN
图片
如上图,通过用户,我们可以拿到他的一些社交兴趣信息,比如他平时喜欢看什么电影,喜欢关注哪些明星,他的好友等等。针对这些信息,通过 Embedding Layer拿到其 embedding。
我们在中间设计了一个网络,叫自组织神经网络,这个网络的用途是将得到的这些 embedding 划分兴趣组,将用户归到兴趣组里面。
具体做法:
(1)第一步通过自组织神经网络,先得到它所属的兴趣组。
自组织神经网络相当于一个权重矩阵,在计算过程中会不断更新。
我们先把用户的这些兴趣特征 embedding汇到网络里面,去得出它所属的兴趣组。公式中Wj 就是自组织神经网络的可训练的权重,根据用户的embedding,去得出用户所属的最接近的兴趣组。
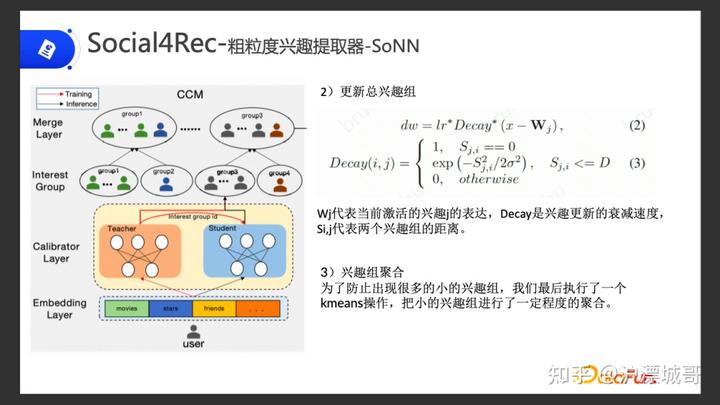
图片(2)第二步根据用户的 embedding 去更新总的用户兴趣组。
更新的方式主要是下面两个公式:把用户的输入去计算出跟整个矩阵组的差值,根据学习率和衰减系数得到更新权重。衰减的系数可以根据公式算出来的。Sj,i 就代表当前兴趣和我们需要计算的另一个兴趣的距离,来得出它所属的范围:
更新权重的方式,在经过几次迭代之后可以更新成一个比较合适的权重矩阵,也可以对每一个用户区分出他的兴趣组。在这个过程中,我们就可以把用户区分到兴趣组上面。
图片(3)第三步兴趣组聚合
兴趣组可能会存在一些情况,太稀疏,每个组里面的人可能很少。我们需要通过 KMeans 的方法,把这些比较稀疏的兴趣组进行小小的聚合。比如可能足球细分类里面又有很多的小类。这些小类的兴趣组里面的用户并不多,我们就需要把他们重新聚合成一个大类,将用户重新归到大的兴趣组里面。
在这一步我们就把用户进行了一个粗的分类,分到了比较大的兴趣组里面。
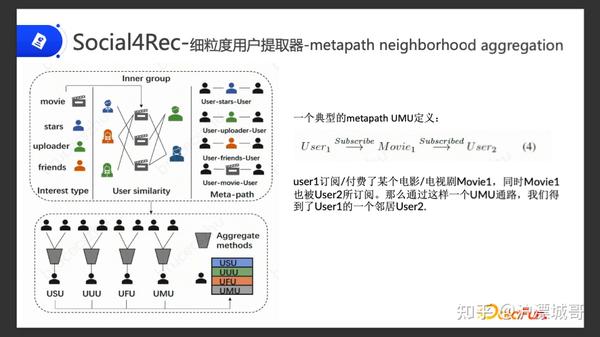
3.Social4Rec-细粒度兴趣提取器-Meta-path neighborhood aggregation
第二个就是进行细分类,通过粗分类我们已经把用户群体归到大的组里面,但这个组会比较大。要在这个大的组里面更精细地去抽取用户的兴趣向量,我们采用了Meta-path 的方法去抽取。
一个典型的 Meta-path UMU 定义为:比如用户订阅电影, User 1 订阅了 Movie 1, User 2 也订阅了 Movie 1,通过 Meta-path 他们两个是可以关联起来的。通过这样的方式,在同一个大的兴趣组里面,我们可以找到这样user1具有关联性的很多个user2用户,我们抽取其中的 top N 的user2用户进行 embedding 的聚合。
top N的用户怎么选取?
直接把它们的初始 embedding 与当前user的embedding算 距离最近的top10,然后将这个 top10 聚合到 user embedding 上面去。

图片
这是具体的计算公式,在兴趣组里面,通过 Meta-path 的方法找最近 top k 的用户,将这些用户的 embedding 聚合起来,再加上自己用户本身的embedding,得到最终的细粒度的用户的 embedding。
因为我们初始的时候是有通过多种兴趣,电影、关注的明星、Up 主、朋友这 4 种关系,所以我们有 4 个 Meta-path 的方法,分别得出了 4 种 Meta-path embedding。每个方式通过聚合自己的embedding、top N 个的邻居 embedding 的向量,得到 4 个 Meta-path 的embedding。最终我们拿这 4 个兴趣向量 embedding 聚合到初始的 YouTube DNN 模型上面。

图片4.兴趣向量聚合
我们的聚合方式:
简单来说,就是把用户兴趣直接 concat 到用户表达上做 attention,之后再经过 MLP 层得到 embedding,然后跟 item 做内积,得到CTR。

图片
这个方式在我们之前的数据集上得到了有效的验证。
之前数据集主要是两个,一个是社交的图, star 代表有多少用户关注明星的 UA 对的数量。Movie 就是用户观看电影的数量。
下面这个是我们主要用的数据集。我们抽取了 15 天的在线的流量日志,前 14 天用于训练,最后一天用于测试。其中区分了冷启动用户的数据,用于单独在冷启动用户上验证效果。
5.总体的效果

图片
总体的效果可以看上图的消融实验数据。
离线部分,在全部用户上面从最初的单独用 YouTube DNN 模型的AUC 0.765,提升到了 0.770。在冷启用户上面的提升更多,将近 2.33 个百分点。
这四个消融实验中三个对照实验代表的含义分别为:
在线部分,我们在所有用户上面去统计了一下,在线CTR提升了 3.6%,在冷启用户上CTR提升了 2%,在点击数量和观看时长上面都分别有比较大的提升。其中冷启用户的提升更多。所以在解决冷启用户问题方面,我们的模型显现出来比较显著的效果。
04 总结
在item推荐中,学术界、业界典型的工作都是如何更好地提取用户直接交互行为信息,而忽视了在真实平台上我们存在的各种各样的信息。Social interest信息在推荐算法中的实用性,这对于在推荐平台上做算法的同学应该是一个特别好的启发,因为我们平台上存在大量的社交信息,有效地利用这些信息将为我们的各种业务带来极大的提升。
05 Q&A
Q1:Meta-path 的定义很大程度决定效果,而 Meta-path 的组合种类很多,怎么根据产品选择?
A1:我们线上拿到了4 种类型的兴趣向量,对于这4种类型,我们分别定义了 4 种 Meta –path,因为根据类型的定义,我们已经很明确,可以得到的只有这 4 种的类型组合。个人认为可以根据当前数据的提供形式来决定到底用什么样的 Meta-path组合,因为在我们的实验当中是很明确的 4种用户可以关联起来的方式,所以我们直接是用的 4 种的,根据电影、明星、关注的 Up 主、好友这四种关系去组合 Meta-path。
Q2:聚类的个数有什么方法确定吗?
A2:聚类的个数,其实刚开始是拍的,主要还是通过调参的方式去判断出聚类数,自组织神经网络聚成一些小类,最开始是定义得比较大的,在大了之后再用 KMeans 去减小它的个数,中间是通过去调整得出来的,其实还主要是超参,超参是调试出来的。
Q3:有没有分析为什么冷启动用户效果更好?
A3:在一个 YouTube DNN 模型里面,冷启动用户能拿到行为序列特征是非常少的。在这种比较少的特征上面,我们抽取出来的社交兴趣的Embedding 是相对比较重的,起到的作用就比较高。所以在冷启动用户上面,我们单独加这个模块效果是更好的。
注:相关代码和论文链接:github.com/xuanjixiao/onerec
