“数据治理”成为最近跟各位大佬们交流中的高频词,大家似乎对数据治理很感兴趣,搜索“数据治理”,网络流传大多是国际数据关系协会制定的DAMA体系等一些标准体系、管理概念。
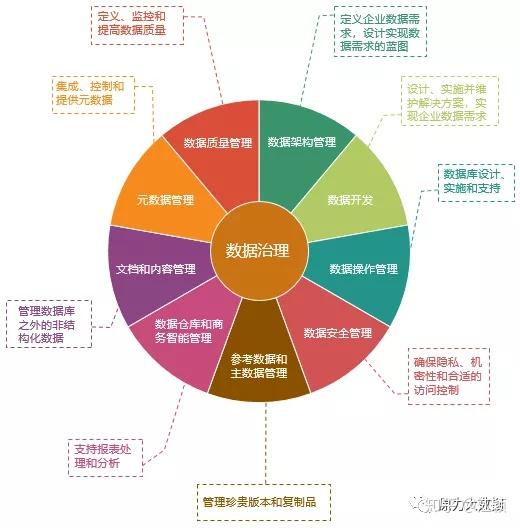
DAMA体系
我们认为,数据治理的最终目的是服务于生产业务,究竟如何把这些标准性、概念性的东西,落地到实践、实操,真正实现数据的“可管、可视、可用、可控、可估”,还需要借助数据平台建设一步步推动企业数据治理落地,直至完善的数据资产管理平台形成。从解决生产业务的支撑问题出发,以可用可操作为宗旨,我们根据企业的实际业务需求,做了许多落地实践的尝试,这里分享2个实践案例,给大家一点思路:
案例1:基于数据中台的理念和方法,做汇集数据中间层,重构数据模型,替代复杂、冗余数据源表
某集团企业需要支撑20多个子公司的日常的数据运营工作, 原力大数据基于数据中台的理念和方法,在集团公司既有的支撑体系内,做了一层数据加工:汇集数据中间层。
将复杂的数据源表简单化,重新构建表关系和指标,接入数据集市的上千张表,上万个数据指标,满足全省各地市的数据支撑需求。
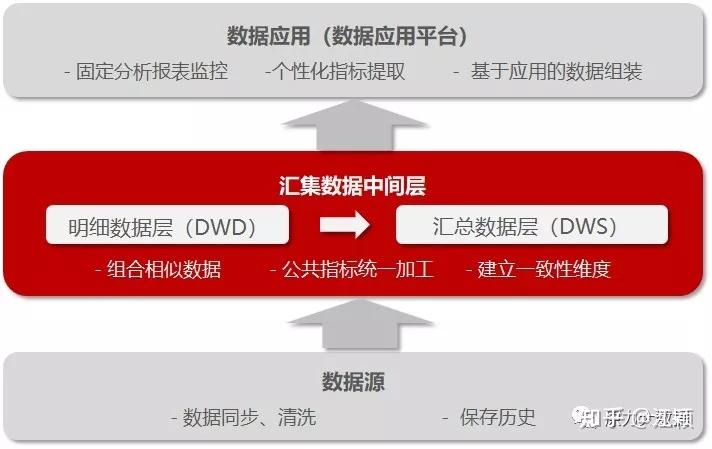
汇集数据中间层的作用:
通过规范化的数据标准与口径,降低了数据理解不一致、计算口径不一致的风险,极大的提升了支撑效率和效益。
这个项目里,我们帮助企业:
1. 将上万个字段,简化成可满足日常使用的1000多个字段,并可以动态管理的字段上架与下架;
2. 将上千张数据表,整理成54张独立的数据表,减少数据存储冗余;
3. 规范数据标准与口径,重新定义了表结构和指标,统一了计算口径,有效降低了理解不一致、调用混乱的风险;
4. 各子公司运营人员能够快速、准确、简单的提取所需数据,学习成本、人力成本、时间成本直接减半。
案例2:建设自主数据分析平台,将数据原子化,支撑业务人员自助选择搭配与计算
原力大数据在与某世界500强集团合作的数据治理项目中,建设了自助分析平台,将数据原子化,构建原子指标库和展示数据指标库。
平台汇集多个来源的数据,基于Kimball维度建模的核心理念,先形成相对标准化的面向业务过程的明细中间表,然后以用户标签表为核心的汇总宽表,再在应用数据层生成个性化指标或数据组装,形成对标签筛选取数、用户画像、个性化分析等应用支撑。

这种数据模型(数据的存储方式)简洁清晰,标准化程度高,易扩展,能大幅节省存储、计算、开发成本;
再搭配‘拖拉拽式’的自助取数功能和可灵活自定义的可视化统计报表,能够满足50-60%的日常运营提数和报表需求。

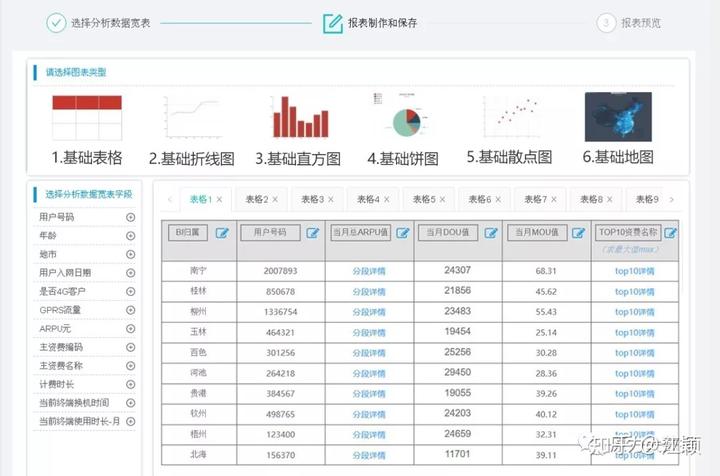
自主分析平台这种数据治理的落地方式,操作模式简单、数据标准与口径标准化程度高、可高度自由配置的指标数据、快速的支撑响应速度,极大的释放了数据支撑人员的压力。
技术活+苦力活,数据治理落地需做好准备
每个企业的数据治理落地路线是“因人而异”的,我们将在接下来的数据治理系列文章中,分享数据治理的实施步骤、数据安全标准、元数据管理、数据标准管理、数据安全管理等。
数据治理既是技术活、也是苦力活。要求团队既懂数据、又懂业务、还有IT建设能力。
原力大数据团队在企业数据治理和数据应用领域已有10多年的项目经验积累,曾帮助多个世界500强企业、龙头企业、政府进行数据治理及数据资产管理,具备从数据、技术、业务应用、管理、安全等方面入手,输出企业大数据治理整套解决方案的能力。
详询微信(ID:jesich)
